

From Model to Data-Centricity in Modern Machine Learning
As data-centricity becomes more important in modern machine learning, it is crucial to prioritize high-quality data over model architecture to improve such systems.

As data-centricity becomes more important in modern machine learning, it is crucial to prioritize high-quality data over model architecture to improve the performance and reliability of Machine Learning (ML) systems
While data science has largely flourished due to the rise of big data and advanced machine learning algorithms, the field still faces the same problem it has since its inception in the 1960s: finding and leveraging high-quality data. This includes data that not only has a sufficient volume to train a ML model, but data that has been stratified, that is representative of different possible slices of the population it was sampled from. Not only that, but also data that has been appropriately cleaned, labeled and engineered.

The most obvious solution is data iteration. After performing error analysis to see which observations an ML model is underperforming for, ML practitioners can see which subset of data they should aim to enrich or augment. Take an example of a speech recognition problem. If there are several different environments where sound is recorded, there may be a particular type of noise present in each environment, and each type may hurt the model’s performance to varying degrees. By adding or augmenting better data for sound samples from environments with the most detrimental noise, the model’s performance can improve to possibly reach human-level predictive performance.

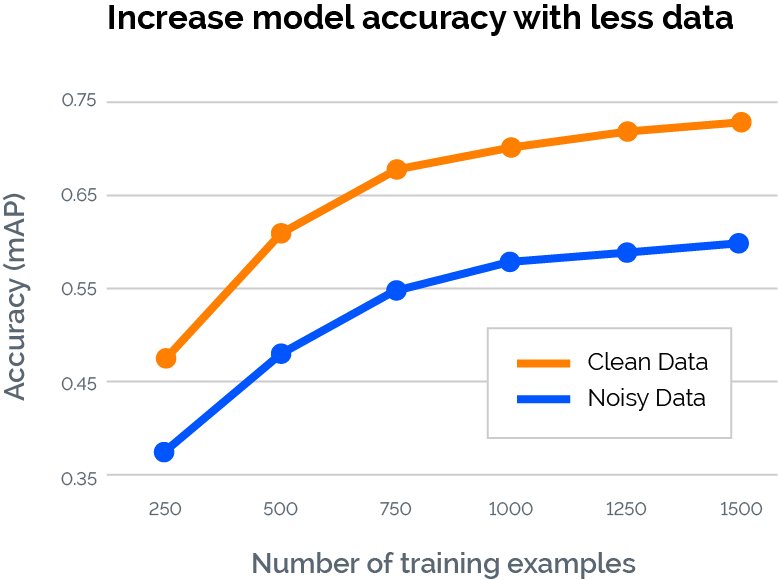{kind=link}
Another major problem with noisy datasets is the presence of poor labels. Models trained on these labels may appear to perform well on training/testing datasets, but go on to fail in production, which may be a partial reason why Gartner estimates around 85% of data science projects fail. Focusing on cleaning noisy labels can help train ML algorithms to reach human-level performance. By focusing on data labeling, using techniques like human-labeling, weak supervision and active learning, datasets with inaccurate labels can be cleaned, often leading to significant gains in model performance.
Well-curated datasets usually undergo a feature engineering process. This is interesting to consider, because the journey of data science has gone from focusing on smaller, hand-crafted datasets with carefully considered features, to focusing on larger datasets with many different features (big data). With this shift from model to data-centricity, the focus has seemingly gone back to this first stage. Feature engineering is necessary to ensure that models are learning from features with high signal to noise ratios, with low or no multicollinearity between features, while also reducing storage and memory needs, by having fewer features and keeping only features that significantly contribute to models’ predictive performance.
Given the advancements in deep learning technologies, it may seem counter-productive to have a data-centric approach. As it happens, simpler models often match the performance of complex ones. Simpler models are more interpretable and in general are less prone to overfitting. They are also, naturally, cheaper to deploy and run than advanced ML algorithms. Being able to train simpler models that still have reliable predictive performance requires the collation of high-quality training data. There are many examples of a focus on data-centric focus leading to better model performance enhancements compared to model-centric focus, including concepts already discussed like data iteration & cleaning labels. In an example illustrated in Andrew Ng’s lectures on “MLOps: From Model-centric to Data-centric AI”, a data-centric approach improved model performance by much wider margins than model-centric approaches (which includes the likes of hyperparameter tuning).

This shift towards data-centricity marks a significant change in the way organizations approach problem solving in data science. By focusing on high-quality data, companies no longer need to rely on complex ML architectures. Instead, by using simpler models that have better data to work with, they can ensure access to more interpretable, reliable, cheaper and faster ML systems. After establishing a reliable data pipeline and data enrichment process, companies can then employ deep learning methods to maximize predictive power even further.